作为一名数据科学家,你已经将大部分时间花在准备数据上。通过这些现实场景,学习如何利用Python中的高级技术:列表推导式、Lambda表达式和Map函数,更快速地完成工作。
在本文中,我将讨论Python的三个重要特性,这些特性对数据科学家非常有用,并能节省大量时间。让我们不再浪费时间,开始吧。
列表和字典推导式
列表和字典推导式是Python中非常强大的工具,有助于创建列表。它节省时间,语法简单,并使逻辑比使用普通的Python for循环更容易。
基本上,它们用于替代显式的for循环,在循环中进行简单的逻辑操作,如附加或处理列表或字典。它们是单行代码,使代码更具可读性。
列表推导式
我们将先看到一个普通的Python示例,然后再看它的列表推导式等价形式。
场景
假设我们有一个简单的Pandas数据框,包含学生在三门科目中的成绩。
In [1]: results = [[10,8,7],[5,4,3],[8,6,9]] In [2]: results = pd.DataFrame(results, columns=['Maths','English','Science'])
如果我们打印它,
In [5]: results Out[5]: Maths English Science 0 10 8 7 1 5 4 3 2 8 6 9
现在假设我们想创建一个包含每门科目最高分的列表,即该列表应该是[10,8,9],因为这些是每门科目的最高分。
Python代码
In [7]: maxlist = [] In [8]: for i in results: ...: maxlist.append(max(results[i]))
如果我们打印它,
In [9]: maxlist Out[9]: [10, 8, 9]
使用列表推导式
列表推导式的基本语法是
[varname for varname in iterableName]
在这里,我们可以对varname进行任何修改。
在我们的例子中,列表推导式是
In [27]:maxlist = [max(results[i]) for i in results]
我们的输出将是
Out[27]: [10, 8, 9]
你看到它如何类似于我们的Python代码了吗?在普通Python代码中,我们是在循环内将max(results[i])附加到maxlist中,而在这里我们不是附加它,而是任何你想要附加的内容都应该是列表推导式中的第一个参数。所以现在我可以将基本语法重写为
newlist = [whatYouwantToAppend for anything in anyIterable]
因此,在我们的例子中,我们想附加数据框每行的最大值,即max(results[i]),所以我们使用
[max(results[i]) for i in results]
字典推导式
同样,我们使用相同的理念进行字典推导式。通常使用的基本语法是
{key, value for key, value in anyIterable}
例如,假设我有一个英文字母的虚拟表,
df =
{0: 'A',
1: 'B',
2: 'C',
3: 'D',
4: 'E',
5: 'F',
6: 'G',
7: 'H',
8: 'I',
9: 'J',
10: 'K',
11: 'L',
12: 'M',
13: 'N',
14: 'O',
15: 'P',
16: 'Q',
17: 'R',
18: 'S',
19: 'T',
20: 'U',
21: 'V',
22: 'W',
23: 'X',
24: 'Y',
25: 'Z'}
现在,如果我们想用数字(0–25)作为字典的值,因为机器学习模型只能处理数字,并且我们想要提供字典值,我们需要交换字典的键和值。交换字典键和值的最简单方法是使用字典推导式。
{number: alphabet for alphabet , number in df.items()}
如果你专注于它一秒钟,就会开始明白它如何反转字典,我们正在循环alphabet和number,这是字典的正常顺序,但我们想要插入的是反序的,所以我们使用number:alphabet而不是alphabet:number。
Lambda表达式
Lambda表达式是数据科学家非常强大的工具。它们非常有用,尤其是在与DataFrame.apply()、map()、filter()或reduce()一起使用时。它们提供了一种避免手动定义函数的简便方法,可以在单行中编写它们,使代码更清晰。
让我们看看Lambda表达式的基本语法,其中我们返回传入函数的任意数字的下一个数字。
z = lambda functionArgument1 : functionArgument1 + 1
在这里,我们的函数参数是functionArgument1,我们返回functionArgument1 +1,这就是下一个数字。
所以使用它,
z(5) >>>6
看,它就是这么简单。让我们看看一个现实世界的例子,我们有一个包含名字的数据框(取自泰坦尼克号数据集),我们想创建一个特征,从名字中提取称谓(如Mr, Miss, Sir等)。
所以,我们的数据框代码是
df = pd.DataFrame([
'Braud, Mr. Owen Harris',
'Cumings, Mrs. John Bradley',
'Heikkeinen, Miss. Laina',
'Futrelle, Mrs. Jacques Heath',
'Allen, Mr. William Henry',
'Moran, Mr. James'
])
数据框是
现在,如果我们注意到一个特定的模式,即在名字后有一个逗号,在我们想要提取的称谓之后有一个句号。我们可以使用列表切片从逗号到句号进行提取。
我们想从逗号后两个索引开始切片,因为我们不想包括逗号和逗号后的空格,所以我们的起始索引是str.find(‘,’)+2,我们想切片到句号(不包括),所以我们将切片到str.find(‘.’)。幸运的是,最后一个索引不包括在内,所以我们不需要显式地从索引中减去1。让我们使用lambda表达式来解决这个问题。
df['Title'] = df[0].apply(lambda a: a[a.find(',')+2: a.find('.')])
在这里,我们使用pandas的.apply函数在df[0]上,即包含所有名字的列。在其中,我们传入一个lambda表达式,该表达式接收每个名字并返回该名字的切片版本。这个切片版本是名字的称谓。现在我们数据框的输出是
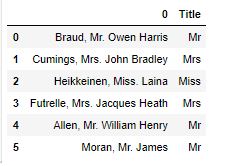
在这里,我们可以看到我们是如何用这个相当清晰的技巧从名字中提取称谓的。
应用于map、reduce或filter时,Lambda表达式非常有用。
Map函数
在Python中,Map函数是非常常用的函数,使我们的工作更加轻松。map的理念是,当在map中传入一个函数和一个可迭代对象时,它会对该可迭代对象的每个单一实体执行该函数。
这是什么意思?
假设我有一个可迭代对象,它是一个包含以下数据的列表[0, 5, 10, 15, 20, 25, 30],以及一个自定义函数isEven(anyInteger),该函数判断传入的anyInteger是否为偶数。如果我们将这个函数和可迭代对象传入map,它将自动对列表中的所有实体应用这个函数,并返回一个map对象,我们可以将其转换为列表、元组或字典。
示例
假设我们的函数是
def isEven(anyInteger): return anyInteger % 2 == 0
我们的可迭代对象是
myList = [0, 5, 10, 15, 20, 25, 30]
如果我们想使用传统方法,则需要遍历我们的列表并对各个项目应用函数。
# 传统方法
isEvenList = []
for i in myList:
isEvenList.append(isEven(i))
这将返回一个新的列表isEvenList,其中偶数为True,奇数为False。
使用map可以使我们的任务更轻松。我们的代码将是
isEvenList = list(map(isEven, myList))
我们的代码就完成了!
在这里,我们在map函数中传入我们的函数isEven和我们的可迭代对象myList,这将返回一个map对象,我们将其转换为list。
map函数的基本语法是
list/dict/tuple(map(myFunction, myIterable))
幸运的是,Pandas提供了map、apply和applymap作为内置函数。它们非常常用且非常有帮助。这三个函数的基本理念与Python内置的map函数相同。你可以在Pandas的官方文档中了解更多关于这些函数的信息。


