当你在构建一个检索增强生成(RAG)应用时,首先需要准备你的数据。你需要:
在Python中,有多种方法可以创建向量嵌入。在这篇文章中,我们将探讨四种生成向量嵌入的方法:本地生成、通过API、通过框架以及使用Astra DB的Vectorize。
本地向量嵌入
在Hugging Face上有许多可用的预训练嵌入模型,您可以使用这些模型来创建向量嵌入。Sentence Transformers (SBERT)是一个库,使得使用这些模型进行向量嵌入以及交叉编码以进行重新排序变得简单。如果您需要,还提供了微调模型的工具。
您可以使用以下命令安装该库:
pip install sentence_transformers一种流行的本地向量嵌入模型是 all-MiniLM-L6-v2。它被训练成一个优秀的全能型模型,可以从一段文本中生成一个384维的向量。
要使用它,导入 sentence_transformers 并使用来自 Hugging Face 的标识符创建模型,在这种情况下是 “all-MiniLM-L6-v2″。如果您想使用一个不在 sentence-transformers 项目 中的模型,比如多语言的 BGE-M3,您也可以使用组织名称来识别模型,例如 “BAAI/BGE-M3″。一旦加载了模型,使用 encode 方法创建向量嵌入。完整代码如下:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
sentence = "A robot may not injure a human being or, through inaction, allow a human being to come to harm."
embedding = model.encode(sentence)
print(embedding)
# => [ 1.95171311e-03 1.51085425e-02 3.36140348e-03 2.48030387e-02 ... ]
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
sentences = [
"机器人不得伤害人类,或者因不作为而使人类受到伤害。",
"机器人必须服从人类给予的命令,除非这些命令与第一法则相冲突。",
"机器人必须保护自己的存在,只要这种保护不与第一法则或第二法则相冲突。",
]
embeddings = model.encode(sentences)
print(embeddings)
# => [[ 0.00195174 0.01510859 0.00336139 ... 0.07971715 0.09885529 -0.01855042]
# [-0.04523939 -0.00046248 0.02036596 ... 0.08779042 0.04936493 -0.06218244]
有许多模型可以使用sentence-transformers库生成向量嵌入,并且由于您是在本地运行,您可以尝试这些模型,以查看哪个最适合您的数据。不过,您需要注意这些模型可能存在的限制。例如,all-MiniLM-L6-v2模型在处理超过128个标记时效果不佳,并且最多只能处理256个标记。另一方面,BGE-M3模型可以编码多达8,192个标记。然而,BGE-M3模型的大小为几个GB,而all-MiniLM-L6-v2则不到100MB,因此也需要考虑空间和内存的限制。
像这样的本地嵌入模型在您在笔记本电脑上进行实验时非常有用,或者如果您有可以加速编码过程的PyTorch硬件。这是一种让您熟悉运行不同模型并查看它们如何与您的数据交互的好方法。
如果您不想在本地运行模型,还有许多可用的API可以用来为您的文档创建嵌入。
API
有几种服务提供将模型作为API嵌入的功能。这些服务包括大型语言模型提供商,如 OpenAI、Google 或 Cohere,以及一些专业提供商,如 Jina AI 或模型托管服务如 Fireworks。
这些API提供商提供HTTP API,通常还提供Python包以便于调用。您通常需要从服务提供商那里获取API密钥。一旦设置完成,您可以通过将文本发送到API来生成向量嵌入。
例如,使用Google的 google-genai SDK 和一个Gemini API密钥,您可以使用他们的 实验性Gemini嵌入模型 生成一个向量嵌入,如下所示:
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="A robot may not injure a human being or, through inaction, allow a human being to come to harm."
)
print(result.embeddings)
每个API可能都不同,尽管许多提供商确实提供与OpenAI兼容的API。然而,每当你尝试一个新的提供商时,你可能会发现需要学习一个新的API。当然,除非你尝试一些旨在简化这一过程的可用框架。
框架
有几个可用的项目,例如 LangChain 或 LlamaIndex,它们在GenAI生态系统的常见组件上创建了抽象,包括嵌入。
LangChain 和 LlamaIndex 都提供了通过 API 或本地模型创建向量嵌入的方法,且接口一致。例如,您可以像上面的代码片段一样使用 LangChain 创建相同的 Gemini 嵌入,如下所示:
from langchain_google_genai import GoogleGenerativeAIEmbeddings
embeddings = GoogleGenerativeAIEmbeddings(
model="gemini-embedding-exp-03-07",
google_api_key="GEMINI_API_KEY"
)
result = embeddings.embed_query("A robot may not injure a human being or, through inaction, allow a human being to come to harm.")
print(result)作为对比,以下是如何使用OpenAI嵌入模型和LangChain生成嵌入的示例:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key="OPENAI_API_KEY"
)
result = embeddings.embed_query("机器人不得伤害人类,或因不作为而使人类受到伤害。")
print(result)我们需要更改导入的名称和使用的API密钥,但其他方面代码是相同的。这使得更换它们并进行实验变得简单。
如果您正在使用 LangChain 构建整个 RAG 管道,这些嵌入与向量数据库接口非常契合。您可以将嵌入模型提供给数据库对象,LangChain 会在您插入文档或执行查询时处理生成嵌入。例如,以下是如何将 Google 嵌入模型与 Astra DB 的 LangChain 封装 结合使用的示例。
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_astradb import AstraDBVectorStore
embeddings = GoogleGenerativeAIEmbeddings(
model="gemini-embedding-exp-03-07",
google_api_key="GEMINI_API_KEY"
)
vector_store = AstraDBVectorStore(
collection_name="astra_vector_langchain",
embedding=embeddings,
api_endpoint="ASTRA_DB_API_ENDPOINT",
token="ASTRA_DB_APPLICATION_TOKEN"
)
vector_store.add_documents(documents) # 要存储在数据库中的文档对象列表您可以使用相同的 vector_store 对象及其相关的嵌入向量来执行向量搜索。
results = vector_store.similarity_search("机器人是否被允许自我保护?")
LlamaIndex 具有类似的抽象层,允许您组合不同的嵌入模型和向量存储。请查看这个 LlamaIndex RAG 介绍 以了解更多信息。
如果您是嵌入的新手,LangChain 提供了一个方便的嵌入模型和提供者列表,可以帮助您找到不同的尝试选项。
直接在数据库中
到目前为止,我们讨论的方法涉及独立于将其存储在向量数据库中或用于搜索向量数据库而创建向量。当您想将这些向量存储在 像 Astra DB 这样的向量数据库 中时,它看起来有点像这样:
from astrapy import DataAPIClient
client = DataAPIClient("ASTRA_DB_APPLICATION_TOKEN")
database = client.get_database("ASTRA_DB_API_ENDPOINT")
collection = database.get_collection("COLLECTION_NAME")
result = collection.insert_one(
{
"text": "机器人不得伤害人类,或因不作为而使人类受到伤害。",
"$vector": [0.04574034, 0.038084425, -0.00916391, ...]
}
)上述内容假设您已经创建了具有适当维度的向量启用集合,以适应您所使用的模型。
执行向量搜索的过程如下所示:
cursor = collection.find(
{},
sort={"$vector": [0.04574034, 0.038084425, -0.00916391, ...]}
)
for document in cursor:
print(document)
在这些示例中,您必须首先创建向量,然后才能使用它们存储或在数据库中进行搜索。在框架的情况下,您可能看不到这一过程,因为它已经被抽象化,但这些操作仍在进行。
使用 Astra DB,您可以在将文档插入集合时或在执行搜索时,让数据库为您生成向量嵌入。这被称为 Astra Vectorize,它简化了您 RAG 流水线中的一个关键步骤。
要使用 Vectorize,您首先需要设置嵌入提供者集成。您可以使用一个内置的集成,无需额外工作;即 NVIDIA NV-Embed-QA 模型,或者您可以选择其他嵌入提供者并通过您的 API 进行配置。
当您创建一个集合时,可以选择要使用的嵌入提供者及所需的维度数量。
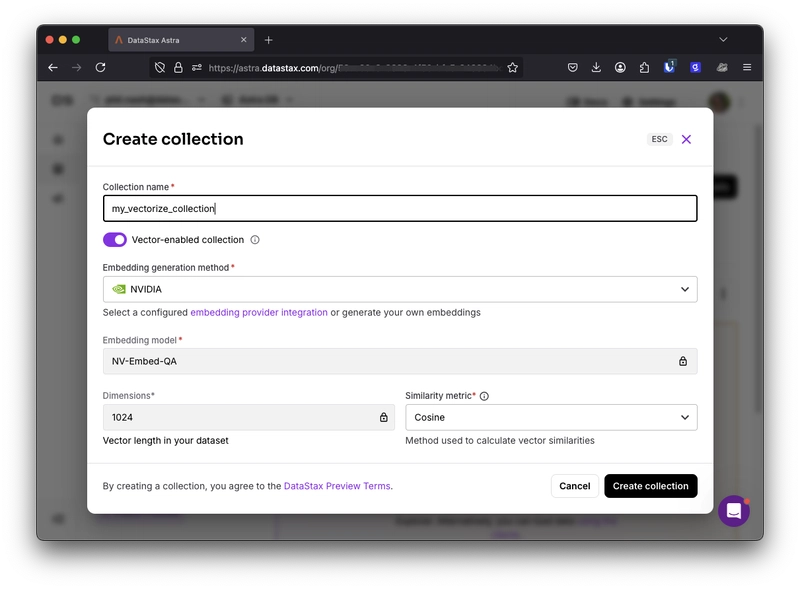
当您以这种方式设置集合时,可以通过使用特殊属性 $vectorize 来添加内容并自动进行向量化。
result = collection.insert_one(
{
"$vectorize": "机器人不得伤害人类,或因不作为而使人类受到伤害。"
}
)然后,当用户查询到来时,可以通过使用 $vectorize 属性进行向量搜索。Astra DB 将创建向量嵌入,然后一步完成搜索。
cursor = collection.find(
{},
sort={"$vectorize": "机器人是否被允许自我保护?"},
limit=5
)这种方法有几个优点:
- Astra DB 团队已经完成了嵌入创建的稳健性工作
- 进行两次单独的 API 调用来创建嵌入并存储它们,通常比让 Astra DB 处理要慢
- 使用内置的 NVIDIA 嵌入模型甚至更快
- 您需要编写和维护的代码更少
向量嵌入选项的世界
正如我们所见,在实现向量嵌入时,您可以做出许多选择,包括使用哪个模型和哪个提供者。这是您 RAG 流水线中的一个重要步骤,花时间找出哪个模型和方法适合您的应用程序和数据是非常重要的。
您可以选择托管自己的模型,依赖第三方API,通过框架抽象问题,或者委托Astra DB为您创建嵌入。当然,如果您希望完全避免编码,那么您可以通过使用Langflow拖放组件来完成。