引言
机器学习(ML)常常让人感觉像一个复杂的黑箱——某种魔法,能够将原始数据转化为有价值的预测。然而,在表面之下,它是一个结构化和迭代的过程。在这篇文章中,我们将分解从原始数据到可部署模型的旅程,涉及模型如何训练、存储其学习到的参数(权重),以及如何在不同环境之间移动它们。本指南旨在帮助初学者理解机器学习项目的整体生命周期。
1. 理解基础知识
什么是机器学习?
在其核心,机器学习是人工智能的一个子集,其中模型通过历史数据“学习”模式。模型不是被明确编程来执行任务,而是随着时间的推移,调整其内部参数(权重)以提高在该任务上的表现。
常见的机器学习任务包括:
- 分类:为输入分配标签(例如,判断一封电子邮件是否为垃圾邮件)。
- 回归:预测连续值(例如,预测房价)。
- 聚类:将相似的项目分组,而无需预定义标签。
机器学习中的关键组件:
- 数据:您的原始输入特征,以及通常对应的期望输出(标签或目标值)。
- 模型:您算法的结构,可能是神经网络、决策树或其他形式的数学模型。
- 权重/参数:模型在训练过程中调整的内部数值,以更好地拟合您的数据。
- 算法代码:更新权重并进行预测的逻辑(通常由像TensorFlow、PyTorch或Scikit-learn这样的框架提供)。
2. 从原始数据到准备训练的数据集
在进行任何学习之前,您必须准备好数据。这包括:
- 数据收集:收集您的数据集。对于房价预测模型,这可能是包含平方英尺、卧室数量和位置等特征的历史销售数据。
- 清洗:处理缺失值,删除重复项,并解决异常值问题。
- 特征工程与预处理:将原始输入转换为更有意义的格式。这可能包括对数值进行归一化、对分类变量进行编码,或提取额外特征(例如根据建筑年份计算房屋的年龄)。
示例(使用Python和Pandas的伪代码):
import pandas as pd
# 加载您的数据集
data = pd.read_csv("housing_data.csv")
# 清洗与预处理
data = data.dropna() # 移除缺失值的行
data['age'] = 2024 - data['year_built'] # 特征工程示例
# 拆分特征和目标
X = data[['square_feet', 'bedrooms', 'bathrooms', 'age']]
y = data['price']3. 选择和训练模型
现在您已经有了干净的数据,您需要选择一个合适的算法。这个选择取决于问题类型(分类与回归)和可用的计算资源等因素。
常见的选择包括:
- 线性/逻辑回归: 简单、可解释的模型,通常用作基线。
- 决策树/随机森林: 擅长处理各种数据类型,通常易于解释。
- 神经网络: 更复杂的模型,能够表示高度非线性的模式(特别是在使用深度学习框架时)。
训练涉及:
- 将数据分为训练集和测试集,以确保模型具有良好的泛化能力。
- 迭代地将训练数据输入模型:
- 模型进行预测。
- 损失函数测量预测值与实际目标之间的误差。
- 优化算法(如梯度下降)更新模型的权重,以减少下一次迭代中的误差。
示例(使用 Scikit-learn):
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 选择一个模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
model.fit(X_train, y_train)
在这个训练循环中,模型更新其内部参数。每次迭代时,它都会调整这些权重,使得预测结果更接近实际期望的输出。
4. 评估和调整模型
一旦模型训练完成,您需要检查它在测试集上的表现——这些数据是在训练过程中未曾见过的。常见的评估指标包括:
- 准确率:用于分类任务(例如,模型正确分类的次数)。
- 均方误差 (MSE):用于回归任务(例如,预测值与实际值之间的平均平方差)。
如果性能不令人满意,您可以:
- 收集更多数据。
- 进行更多特征工程。
- 尝试不同的超参数或切换到更复杂的模型。
- 采用正则化或其他技术以防止过拟合。
示例:
from sklearn.metrics import mean_squared_error
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print("均方误差:", mse)5. 保存训练好的模型
在模型表现良好后,您会想要保存它。保存可以保留模型的架构和学习到的权重,使您能够在不重新训练的情况下稍后重新加载它。具体格式取决于所使用的框架:
-
- Scikit-learn: 通常使用
pickle或joblib文件(.pkl或.joblib)。
- Scikit-learn: 通常使用
-
- TensorFlow/Keras: 通常使用
.h5文件或 SavedModel 格式。
- TensorFlow/Keras: 通常使用
-
- PyTorch: 将模型状态字典保存为
.pth或.pt文件。
- PyTorch: 将模型状态字典保存为
示例(使用 joblib):
import joblib
joblib.dump(model, "trained_model.joblib")
6. 在新机器上部署和使用模型
如果您需要在另一台机器或服务器上使用该模型怎么办?只需将保存的模型文件传输到新环境并在那里加载即可:
在新机器上:
import joblib
# 加载模型
loaded_model = joblib.load("trained_model.joblib")
# 准备新的输入数据(与之前相同的预处理步骤!)
new_data = [[2000, 3, 2, 20]] # 示例特征
# 进行预测
prediction = loaded_model.predict(new_data)
print("预测价格:", prediction)
当你运行 loaded_model.predict() 时,模型会使用存储的权重和架构为新的输入生成输出。关闭终端时不会丢失任何内容——你训练的模型参数安全地存储在你刚刚加载的文件中。
7. 端到端总结
总结一下:
- 数据准备: 收集并预处理你的数据。
- 模型训练: 选择一个算法,通过输入数据和调整权重进行训练。
- 评估: 检查在测试数据上的表现,并在必要时优化模型。
- 保存模型: 持久化训练好的模型的架构和参数。
- 部署与预测: 将保存的模型移动到新环境,加载它,并在新数据上进行预测。
这个管道几乎是每个机器学习项目的核心。随着时间的推移,随着经验的积累,你会探索更复杂的工具、云部署以及像机器学习模型的持续集成(MLOps)这样的高级技术。但核心概念始终不变:机器学习模型从数据中学习模式,存储这些学习到的参数,并在部署的地方利用它们进行预测。
可视化机器学习管道
为了帮助你可视化整个流程,这里有一个简单的图示,展示了我们讨论的主要步骤:
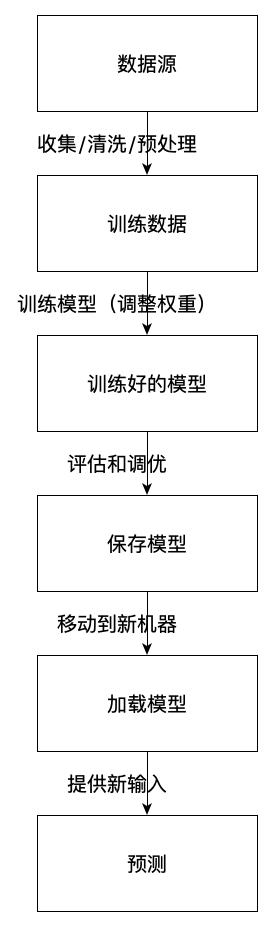
结论
通过理解这些基本步骤,您已经揭开了机器学习“黑箱”的面纱。虽然每个步骤都有更深的内涵——高级数据预处理、超参数调优、模型可解释性和MLOps工作流——但这里描述的框架提供了一个坚实的起点。随着您信心的增强,可以随意深入探索并尝试不同的技术、库和范式,以完善您的机器学习项目。


