首页 › 论坛 › 置顶 › 基于AI的搜索:Python、MongoDB与OpenAI的结合
-
作者帖子
-
2025-03-07 16:46 #13552Q QPY课程团队管理员
随着过去几年人工智能技术的进步,显然它将持续存在,并已经开始影响我们的生活以及我们与技术的互动。
相似性搜索是一种可以轻松实现的技术,它为信息搜索提供了一种新方法,将自己的数据库与语言模型的强大能力结合起来。在本文中,将解释相似性搜索及其一些基本概念,并提供一个使用Python、MongoDB和OpenAI API实现电影推荐系统的实用示例。希望这能帮助其他人更好地理解语言模型的众多实际应用之一。
该项目的灵感来源于freeCodeCamp的相关视频。感谢freeCodeCamp提供了如此出色的免费学习资源!
相似性搜索
这是一种通过其意义来搜索文本数据的方法。与常规数据库搜索相比,这最初是一个令人困惑的概念。通常情况下,您会寻找文本匹配以找到相似的单词,类似于正则表达式,但语义意义则有所不同。想想“海”和“洋”这两个词——它们是完全不同的词,但具有相似的意义和共享的上下文,这使得它们在意义上彼此接近。
但是,我们如何告诉我们的软件程序两个不同的词或句子具有相似的意义呢?由于这是一个人类的概念,一些非常聪明的人想出了一个将意义以计算机可以理解的方式表示的方法:向量嵌入。
向量嵌入
本质上,向量是数字的数组。然而,它们真正的力量在于将人类语言所感知的意义转化为向量空间中的接近度。解释向量空间的概念超出了本文的目的。现在,了解彼此接近的向量代表相似的意义就足够了。

要将文本转换为向量,我们需要使用文本嵌入模型,这是一种经过训练的机器学习模型,旨在将一段文本转换为表示其含义的数字数组。像Word2Vec、GLoVE和BERT这样的模型能够将单词、句子或段落转换为向量嵌入。图像、音频和其他格式也可以转换为向量,但我们暂时只关注文本。要了解更多关于向量嵌入的信息,请查看Pinecone提供的这篇优秀文章,Pinecone是一家向量数据库提供商。
MongoDB的向量搜索
MongoDB 是一个能够大规模存储非结构化数据的 NoSQL 数据库。它使用类似 JSON 的格式来存储具有动态模式的文档,使其灵活地存储几乎任何类型的数据,而传统的 SQL 数据库则要求数据以表格形式结构化,这一点较为困难。
在 MongoDB 中可以存储的内容之一是向量嵌入,我们已经知道这只是数字数组。此外,MongoDB 在其数据库中实现了 向量搜索,这使我们能够执行相似性搜索。
要执行相似性搜索,我们需要两个要素:一个 查询向量,表示我们要寻找的内容,以及一个 向量数据库,表示我们可能的相似向量的宇宙。因此,在这种情况下,我们需要将来自应用程序用户的自然语言查询嵌入到一个向量中。我们还需要拥有包含嵌入数据的数据库。
我们可以使用像 K-最近邻这样的搜索算法来找到与我们的查询向量更接近的数据库向量,并确定在我们的搜索空间中哪些是最有意义的匹配。
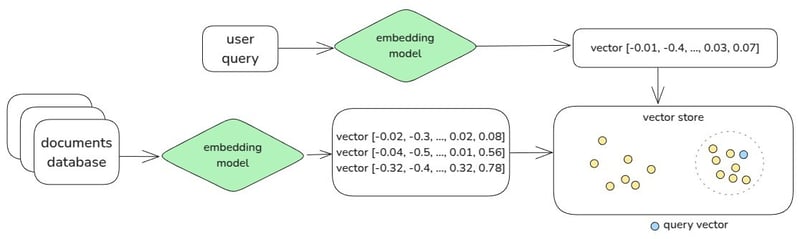
希望通过实际的实现,这一点会变得更加清晰。让我们开始吧。
生成嵌入
在这个例子中,我们将使用Mongo的示例电影数据库,具体来说是数据库
sample_mflix和集合embedded_movies,该集合包含关于电影的数据,包括标题、演员、情节等。示例数据在您创建新集群时会提供加载。如果您不确定如何创建新的Mongo集群,请按照文档中的步骤创建一个免费集群并连接到它。该集合的示例数据已经包含一个名为
plot_embdding的字段,该字段包含plot字段的嵌入。在这种情况下,该字段是由 OpenAI 的 text-embedding-ada-002 模型生成的,该模型生成包含 1536 个数字的数组。 不同的模型将输出不同大小的数组。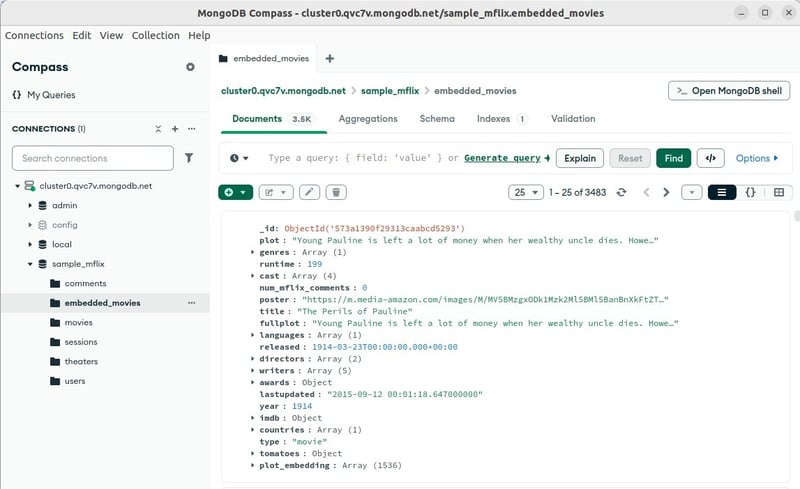
在一个类似生产的环境中,如果您想使用自己项目的数据,您需要生成嵌入并将其保存到数据库中,这可以通过多种方式实现。在这个例子中,为了方便,我们将使用样本数据中已经存在的嵌入,但我们也可以使用开源模型通过库sentence-transformers生成嵌入。例如,MongoDB的文档中有一个关于如何为您的数据创建嵌入的全面部分。
请记住,生成嵌入可能是计算密集型的,如果您要为整个数据库(尤其是大型数据库)执行此操作,必须制定一个良好的策略。
OpenAI的嵌入API模型并不是免费的,您需要注册一个账户并为其充值才能使用,这也是我为这个项目所做的。这可能适合生产环境,因为它是一个可靠的AI模型供应商,但使用开源模型也是一个不错的策略。这一切都取决于项目的需求。
由于我们已经嵌入了数据库字段,现在我们需要创建一个函数来生成搜索查询的向量。我们应该使用与数据库其余部分相同的模型——主要是因为我们需要在向量中保持相同大小的数组,同时使用不同的模型可能会影响搜索结果的质量。我们需要获取一个OpenAI API密钥,并将其设置在我们的环境变量中。请记住,绝不要将API密钥上传到公共代码库!
# generate_embeddings_openai.py from openai import OpenAI from dotenv import load_dotenv import os load_dotenv(override=True) openai_key = os.getenv("OPENAI_API_KEY")client = OpenAI(api_key=openai_key) def generate_embedding_openai(text: str) -> list[float]: response = client.embeddings.create( model="text-embedding-ada-002", input=text, encoding_format="float" ) return response.data[0].embedding在这段代码中,我们首先创建了一个 OpenAI 客户端,并定义了一个名为 `generate_embedding_openai` 的函数,该函数接受一个字符串类型的参数 `text`。该函数的返回值是一个浮点数列表。函数内部调用了客户端的 `embeddings.create` 方法,指定了模型为 `text-embedding-ada-002`,输入为传入的文本,并设置编码格式为 `float`。最后,函数返回响应中的嵌入数据。
在运行向量搜索之前,我们需要在MongoDB数据库中创建搜索索引,这可以通过Mongo界面或通过Python中的
pymongo包以编程方式完成。索引是高效执行搜索的重要部分。from pymongo.mongo_client import MongoClient from pymongo.operations import SearchIndexModel import time from dotenv import load_dotenv import os load_dotenv(override=True) # Connect to your Atlas deployment uri = os.getenv("MONGODB_URI") client = MongoClient(uri) # Access your database and collection database = client["sample_mflix"] collection = database["embedded_movies"] # Create your index model, then create the search index search_index_model = SearchIndexModel( definition={ "fields": [ { "type": "vector", "path": "plot_embedding", "numDimensions": 1536, "similarity": "dotProduct", "quantization": "scalar" }, { "type": "filter", "path": "genres" }, { "type": "filter", "path": "year" } ] }, name="plot_embedding_vector_index", type="vectorSearch", ) result = collection.create_search_index(model=search_index_model) print("New search index named " + result + " is building.") # Wait for initial sync to complete print("Polling to check if the index is ready. This may take up to a minute.") predicate=None if predicate is None: predicate = lambda index: index.get("queryable") is True while True: indices = list(collection.list_search_indexes(result)) if len(indices) and predicate(indices[0]): break time.sleep(5) print(result + " is ready for querying.") client.close()现在我们拥有进行搜索所需的一切:我们的嵌入式数据库、嵌入式用户查询以及在适当字段中创建的搜索索引。有了这些,搜索可以如下进行:
# query_movies.py import pymongo from dotenv import load_dotenv import os from generate_embedding_openai import generate_embedding_openai load_dotenv(override=True) mongodb_uri = os.getenv("MONGODB_URI") client = pymongo.MongoClient(mongodb_uri) db = client["sample_mflix"] collection = db["embedded_movies"] query = 'movies about war in outer space' query_embedding = generate_embedding_openai(query) results = collection.aggregate([ { "$vectorSearch": { "queryVector": query_embedding, "path": "plot_embedding", "numCandidates": 1000, "limit": 4, "index": "plot_embedding_vector_index" } } ]) for r in results: print(f'Movie: {r["title"]}nPlot: {r["plot"]}nn')向量搜索查询有几个参数,包括:
queryVector:用户查询的向量表示,在本示例中,我们使用与嵌入数据库其余部分相同的模型嵌入了查询“关于外太空战争的电影”。path:执行向量搜索的集合字段。numCandidates:可能的结果数量,这些结果是用户查询的候选最近结果。limit:我们将从候选结果中返回的前几个结果的数量。这些是向量空间中与查询最接近的结果。index:我们刚刚创建的搜索索引。
结果与结论
在运行我们的脚本 query_movies.py 时,我们得到了以下结果:
电影:25世纪的巴克·罗杰斯情节:一名20世纪的宇航员从500年的悬浮动画中苏醒,进入一个地球受到外星入侵者威胁的未来。 电影:Farscape: The Peacekeeper Wars 情节:当邪恶的斯卡兰帝国发动全面战争时,和平卫士联盟只有一个希望:重新组建人类宇航员约翰·克里顿,他曾被吸入和平卫士银河系…… 电影:Space Raiders 情节:一个未来主义的敏感冒险故事,讲述一个10岁男孩被一艘充满杂牌空间海盗的飞船意外绑架的经历。 电影:V: The Final Battle 情节:一小群人类抵抗战士与统治地球的种族灭绝外星人展开绝望的游击战。我们可以注意到,所有四个结果都与外太空战争相关的图表,包括一些甚至没有共享相同关键词的图表,这证明了我们的观点:这并不是一个简单的文本搜索。这种基于意义的搜索是一个强大的工具,可以帮助您创建更复杂的应用程序。
这种方法的真正价值在于,您可以利用自己的专有数据进行这种类型的搜索,从而为用户提供更好的结果,并为您的应用程序增加价值。
-
作者帖子
- 哎呀,回复话题必需登录。