内存管理是编程中最重要但常被低估的方面之一。大多数开发者专注于功能和特性,往往忽视这一隐秘的基础,直到问题出现。糟糕的内存管理会导致程序运行缓慢、无预警崩溃,或者逐渐消耗更多内存直到失败。
然而,与 C、C++ 和 Java 等其他编程语言不同,开发者必须显式地分配和释放内存,Python 通过引用计数和垃圾回收自动化了这一过程。
在本文中,我们将深入讨论 Python 的内存管理系统。我们将首先介绍 Python 如何组织内存,然后理解引用计数及其局限性,最后讨论垃圾回收如何解决这些问题。
以下是概述:
- Python 如何组织内存(栈内存和堆内存)
- Python 的主要内存管理:引用计数
- 引用计数的局限性
- Python 的垃圾回收系统
- 内存优化的实用策略
- 实际应用和性能考虑
在学习Python如何跟踪和清理内存之前,了解内存的结构是至关重要的。我们先从Python如何组织内存的基本知识开始。
Python中的内存组织
为了有效处理内存分配,Python将内存组织为两个主要区域:
- 栈内存:用于存储函数调用、局部变量和控制流。它是自动管理的,内存会在函数执行时自动分配和释放。
- 堆内存:用于动态分配的对象,如列表、字典和用户定义的实例。这些对象会一直保留在内存中,直到不再需要。
栈内存
栈内存处理函数调用、局部变量和对象引用。每次调用函数时,都会创建一个新的栈帧,用于存储:
- 函数参数
- 局部变量(指向对象的名称)
- 控制流信息
一旦函数完成,栈帧将被丢弃,其引用也会被移除。
例如:
def example():
x = [10, 20, 30] # 'x' 存储在栈内存中
return x
result = example() # 'result' 现在引用返回的列表
在这里,x 在函数执行期间存在于栈内存中,但列表 [10, 20, 30] 是在堆内存中创建的。当函数返回时,x 从栈中移除,但由于 result 仍然引用该列表,因此它仍然保留在堆内存中。
堆内存
所有动态分配的对象(列表、字典、自定义对象)都存储在堆内存中。只要引用存在,这些对象在函数执行结束后仍然存在。
x = [5, 6, 7] # 列表是在堆内存中创建的
在这个例子中:
列表 [5, 6, 7] 存储在堆内存中,而名称 x 存储在栈内存中,并作为对堆对象的引用
现在我们了解了内存的组织方式,让我们来看看 Python 如何通过计数引用来跟踪这些堆对象。
Python 的主要内存管理:引用计数
在许多编程语言中,例如 C、C++ 和 Java,变量和对象是不同的——变量直接存储值或指向对象的内存地址。然而,在 Python 中,变量仅仅是引用内存中对象的名称(标签),而不是直接存储值。Python 使用 引用计数 来跟踪有多少个名称指向给定对象,因为多个名称可以引用同一个对象。
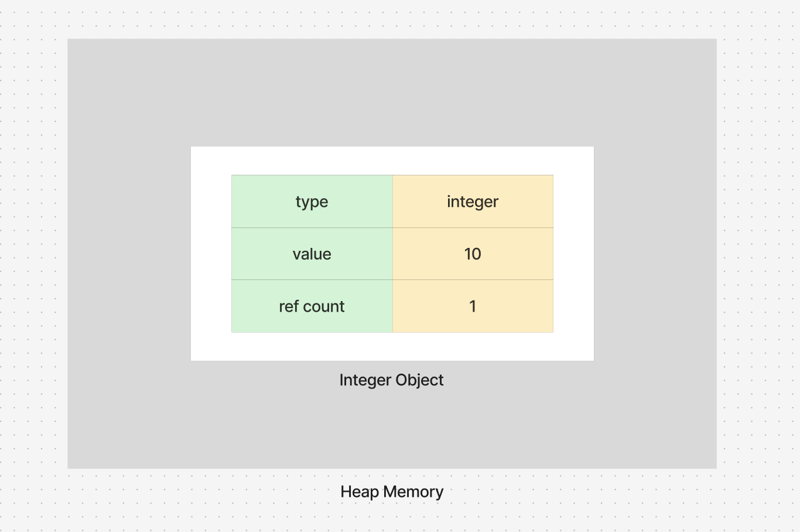
Python 中的每个对象由三个关键属性组成:
- 类型:对象的数据类型由 Python 自动推断
- 值:存储在对象中的实际数据
- 引用计数:指向该对象的引用(或名称)的数量。
Python 提供了一个 sys.getrefcount() 函数,可以用来检查对象的引用计数:
import sys
a = [1, 2, 3]
print(sys.getrefcount(a)) # 输出: 2 (一个是 'a',一个是函数参数)
计数为 2,因为调用 sys.getrefcount(a) 会暂时创建另一个引用作为函数参数。
每当创建一个新引用时,引用计数会增加,而每当删除或重新分配一个引用时,引用计数会减少。
例如:
a = [1, 2, 3] # 引用计数:1
b = a # 引用计数:2('a' 和 'b' 都引用同一个列表)
a = None # 引用计数:1(现在只有 'b' 引用该列表)
del b # 引用计数:0(没有剩余引用)
当一个对象的引用计数降至零时,Python会自动释放内存,使其可供未来使用。这种自动清理是Python内存管理系统的一大优势。
引用计数的优势
引用计数作为一种内存管理策略,提供了几个好处:
- 即时清理 – 当一个对象的引用计数达到零时,它会立即被释放,从而防止过度的内存消耗。
- 简单性 – 该机制简单明了,不需要复杂的后台处理。
- 确定性行为 – 由于对象在变为无引用后立即被释放,我们可以预测内存何时会被释放。
然而,尽管有这些优点,仅依靠引用计数并不足以实现全面的内存管理。让我们来看看它的局限性。
引用计数的局限性
虽然引用计数有效地处理了大多数内存管理场景,但它有几个显著的局限性:
- 性能开销:增加和减少引用计数会带来小但恒定的性能成本,尤其是在大型应用程序中。
- 非线程安全:由于潜在的竞争条件,引用计数在多线程程序中可能会导致问题。
- 循环引用:最大的局限性是,相互引用的对象会使它们的引用计数保持在零以上,从而阻止自动释放。
循环引用的问题值得特别关注。
考虑这个例子:
class Node:
def __init__(self):
self.ref = None
a = Node()
b = Node()
a.ref = b # 'a' 引用 'b'
b.ref = a # 'b' 引用 'a'
del a
del b # 由于循环引用,对象仍然存在
在这段代码中,即使删除了变量 a 和 b,Node 对象本身仍然存在于内存中,因为它们相互引用,使得它们的引用计数保持在 1,而不是 0。这就造成了一个内存泄漏,单靠引用计数无法解决。
因此,循环引用问题代表了引用计数的一个基本限制,需要额外的机制来解决。这就是 Python 的垃圾回收系统作为引用计数的补充解决方案发挥作用的地方。
Python 的垃圾回收系统
垃圾回收 (GC) 是 Python 的补充内存管理系统,它与引用计数一起工作,以清理不再使用的对象,特别是那些涉及循环引用的对象。它释放分配给未使用对象的内存,防止内存泄漏。
代际垃圾回收
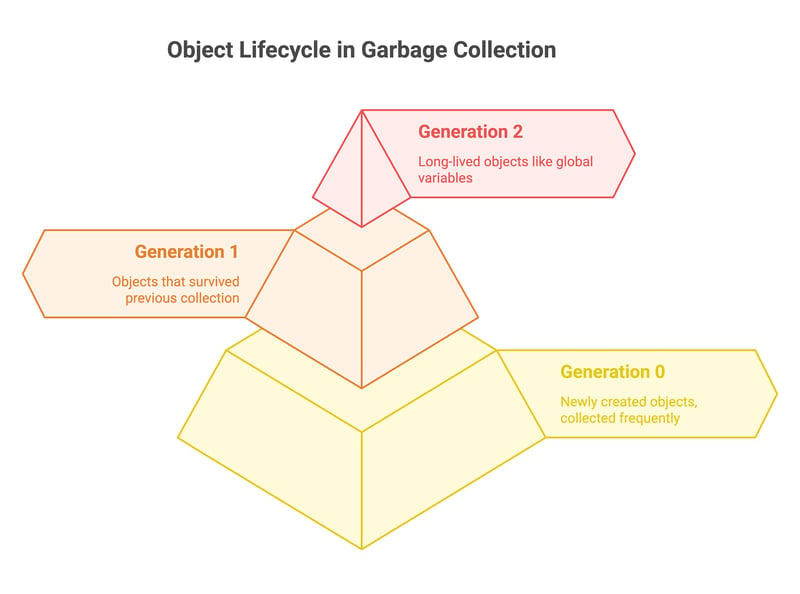
Python的垃圾回收采用代际方法来优化性能。这个理念是大多数对象的生命周期较短,因此频繁回收它们可以提高效率。
垃圾回收器根据对象的年龄将其分为三代:
- 第0代(最年轻):新创建的对象。回收频率最高。
- 第1代(中间年龄):在之前的回收中存活下来的对象。
- 第2代(最老):生命周期较长的对象,如全局变量和缓存数据。
垃圾回收的工作原理逐步解析
1. 从第0代(最年轻对象)开始
- 当垃圾回收运行时,它首先检查第0代,其中包含最新的对象。
- 由于短生命周期的对象(例如,函数中的临时变量)最有可能迅速变成垃圾,因此这一步有助于有效地释放内存。
2. 存活的对象会被提升
- 如果一个对象在一次回收后仍然被引用,它将被移动到下一代(第1代),而不是被删除。
- 这意味着Python假设,如果一个对象在一次垃圾回收中存活下来,它可能会被需要更长时间。
- 类似地,在第1代中存活下来的对象会被提升到第2代。
3. 第2代(长生命周期对象)最少被回收
- 由于第2代中的对象已经经历了多次回收,Python假设它们是重要的,并且不太可能成为垃圾。
- 因此,第2代的回收频率最低,从而减少了性能开销。
- 这类对象的例子包括模块级变量、全局缓存和持久数据结构。

这种增量回收方式在保持内存使用效率的同时,防止了不必要的性能开销。
检测和打破循环引用
Python的垃圾回收器定期扫描内存,以查找相互引用但不再被程序其他部分访问的对象。
以下是它如何在我们之前的示例中工作的:
import gc
class Node:
def __init__(self):
self.ref = None
a = Node()
b = Node()
a.ref = b
b.ref = a
del a
del b # 对象由于循环引用仍然存在
gc.collect() # 手动触发垃圾回收
在这里,调用 gc.collect() 强制 Python 扫描循环引用。垃圾回收器识别出两个 Node 对象形成了一个程序无法再访问的引用循环,并将其移除,从而释放内存。
垃圾回收何时运行?
Python 的垃圾回收器会根据阈值系统在后台自动运行:
- 如果对象分配的数量超过设定的限制,则会触发一个回收周期。
- 开发者可以使用
gc.collect()手动触发垃圾回收,尽管这通常不需要。 - 如果在特定情况下需要性能优化,垃圾回收器也可以通过
gc.disable()被禁用。
虽然引用计数大多数情况下能够立即处理内存释放,但垃圾收集器提供了一个安全网,可以捕捉循环引用和其他引用计数无法解决的复杂内存问题。
性能考虑
虽然Python的垃圾收集系统通常是高效的,但频繁的垃圾收集周期可能会导致轻微的性能下降,尤其是在内存密集型应用程序中。
我们还可以使用gc模块微调收集行为:
- 使用
gc.set_threshold()调整阈值。 - 使用
gc.get_stats()监控收集统计信息。 - 在性能关键的部分禁用自动收集,并手动运行它。
现在我们了解了Python的内存管理,让我们看看优化应用程序内存使用的实用策略。
在Python中优化内存管理
虽然Python的垃圾收集系统自动处理内存清理,但未优化的内存使用可能会导致性能瓶颈。
以下策略有助于更有效地管理内存:
避免不必要的对象创建
不必要地创建过多对象会增加内存使用,并对Python的垃圾回收器造成压力。使用内存高效的技术,例如使用生成器而不是列表,可以显著减少内存消耗。
示例:使用生成器而不是列表
# 列表一次性为所有元素消耗内存
squares_list = [x * x for x in range(1000000)]
# 生成器按需计算值,减少内存使用
squares_generator = (x * x for x in range(1000000))
由于生成器一次生成一个值,它们可以防止在内存中存储大型列表,因此非常适合遍历大型数据集。
高效处理循环引用
循环引用发生在对象相互引用时,导致引用计数无法降到零。虽然Python的循环垃圾回收器能够检测并清理这些对象,但使用弱引用可以帮助打破引用循环并优化内存使用。
示例:使用弱引用来防止循环
import weakref
class Example:
pass
obj = Example()
weak_ref = weakref.ref(obj) # 创建一个弱引用而不是强引用
与普通引用不同,弱引用不会增加引用计数。一旦一个对象没有剩余的强引用,它会被自动垃圾回收,即使弱引用仍然指向它。
在必要时禁用或控制垃圾回收
在高性能应用程序(如实时系统或机器学习工作负载)中,自动垃圾回收可能会导致性能开销。暂时禁用它并在受控的时间间隔内进行手动回收可以有所帮助。
示例:禁用垃圾回收
import gc
gc.disable() # 禁用自动垃圾回收
# 执行高性能操作...
gc.collect() # 在需要时手动触发垃圾回收
gc.enable() # 重新启用自动垃圾回收
这种方法在频繁的垃圾回收周期干扰性能敏感操作时非常有用。
监控内存使用情况
跟踪内存分配有助于识别内存泄漏并优化内存使用。Python 提供了像 tracemalloc 和 objgraph 这样的工具来有效监控内存使用情况。
示例:使用 tracemalloc 跟踪内存使用情况
import tracemalloc
tracemalloc.start()
# 代码执行
print(tracemalloc.get_traced_memory()) # 显示当前和峰值内存使用情况
tracemalloc.stop()
通过分析内存快照,开发者可以识别并优化消耗过多内存的对象。
现实世界应用
在多个场景中,理解Python的内存管理变得尤为重要:
数据处理应用
在处理大型数据集时,高效的内存管理可能是应用程序正常运行与因内存错误崩溃之间的区别。使用生成器、分块数据和批处理等技术可以显著减少内存占用。
长时间运行的服务
即使是小的内存泄漏也会随着时间的推移而累积,导致持续运行的服务器应用程序和微服务出现故障。定期对内存使用情况进行分析和监控有助于及早识别和修复这些问题。
资源受限环境
在内存有限的环境中(如嵌入式系统、内存限制严格的无服务器函数),了解Python如何管理内存可以帮助开发人员编写更高效的代码,避免达到资源限制。
结论
Python的内存管理系统通过引用计数提供即时清理,并通过垃圾回收实现全面的泄漏防止。这种双重方法确保内存的高效使用,并且对开发人员的手动干预要求最小。
然而,单靠自动内存管理并不总是最佳选择。了解Python如何处理内存使我们能够编写更高效、高性能的应用程序。
通过最小化不必要的对象创建、使用弱引用、控制垃圾回收和监控内存使用情况,我们可以防止过度的内存消耗并提高应用程序性能。深思熟虑的内存管理不仅仅是避免泄漏,更是编写可扩展、优化代码的关键。
下次当你调试内存问题或优化Python应用程序时,请记住底层内存管理的工作原理。这些见解可以帮助你做出更好的设计决策,并创建更高效的软件。


